What types of data are suitable for Visplore?
Visplore is optimized for data from time-dependent measurements. Typical examples include:
- Sensor data from machinery (e.g. industrial processes)
- Time series of energy production / consumption
- Meteorological time series
- Price time series
- Product quality samples
- Scientific experiments
- Incidents such as alerts
Data model
Visplore assumes data to be structured as a table (or "data matrix"), as it is common in statistics, data bases, and spreadsheet programs like Excel.
Rows of this data table represent data records. Each data record has the same structure, like a set of conducted measurements (as columns, see below). They are often characterized by a point in time (e.g. the "time stamp") or other key information for unique identification.
Columns of the data table are the data attributes, given for each row. For instance, the physical quantities measured by different sensors at each point in time (see example below). Data attributes may be:
- Quantitative (e.g., measured value)
- Categorical (e.g., "on/off", different product types, "ok/not ok", error types, etc.)
- Time stamps
Examples
The examples below show how typical data tables can look like for import into Visplore:
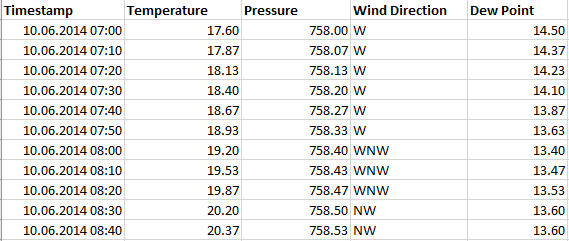
Example 1: Meteorological time series - with equal step size of 10 min
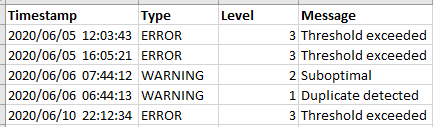
Example 2: Log of alerts - irregular time stamps
Example 3: Dataset of 4 wind turbines in long format - the same time stamp occurs in many rows
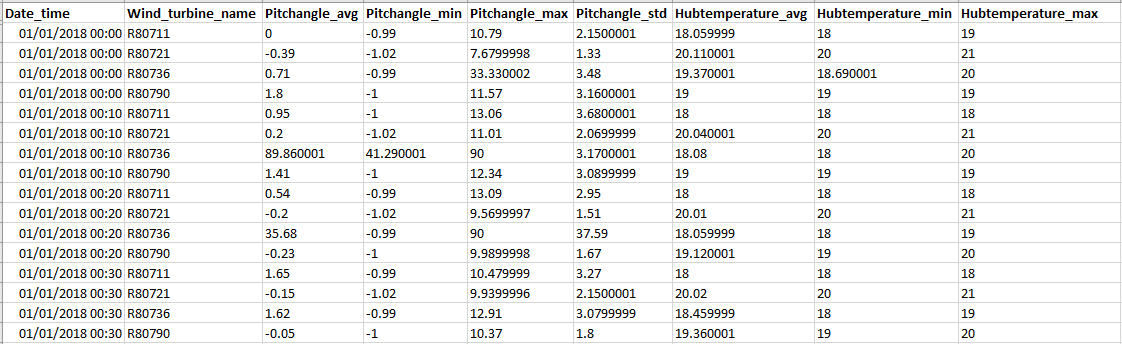
See this use case tutorial on how to work with tables in long format.
Further aspects
Most types of visualization show a few data attributes at the same time, for example a scatter plot of two measured quantities. The default is to visualize all data records. However, it is possible to select or filter subsets of records, for example corresponding to certain time periods. Selecting subsets of records is the primary mechanism of linking multiple views on the data in Visplore.
Visplore supports missing values. It is thus ok if some data attributes are not specified for several records.
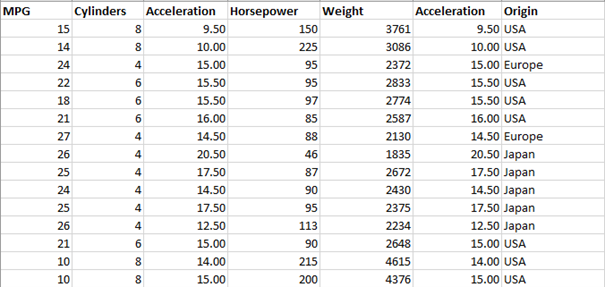
Furthermore, Visplore is not limited to time-oriented data. It is ok to load data that does not have any time stamps! Visplore can thus be used to, for example, analyze large sets of objects such as products, artefacts, etc. Such data could look like the following example of cars:
Limitations
You can only import one data table at a time into Visplore (with up to millions of rows and hundreds of columns).
The following scenarios are common examples requiring pre-processing outside Visplore:
- Analyzing time series data from multiple sources (e.g., multiple files) with different step sizes.
- Analyzing discrete events and continuous sensor time series together, at the same time.
- Joining multiple relational data tables.
CSV files
For loading data from CSV files, some additional aspects need to be considered:
- The names of the data attributes are supposed to be represented as a single line. This is often the first line of the file, but Visplore also supports skipping lines before the line containing the attribute names. It is currently not possible to compose names of data attributes by combining multiple lines.
- Units may optionally be specified in the line beneath the attribute names.
- All subsequent lines are assumed to contain the actual data.
- Visplore tries to guess the data types for each data attribute. In some cases, however, data attributes with categorical semantics contain values and are thus assumed as value-typed. In such cases, it makes sense to manually switch the data type of the data attribute to "categorical".
- Time stamps are easier to handle if they are given as a single data column containing both date and time. If the date and the time are represented as two separate data columns, a derived data attribute that combines the two can be computed in a Visplore cockpit: Click "New data attribute..." in the toolbar to create a "Date/Time attribute". Then use the CombineDatetime() function in the formula editor.
- Visplore tries to recognize special characters from the data, in particular the characters used for (1) separating the data columns, (2) the decimal comma, and (3) digit grouping, if any. In some ambiguous cases, however, it can be necessary to manually override the assumed characters for correct import. It is required that these characters are used consistently throughout the file.
In Example 3, the ENGIE La Haute Borne windfarm dataset is used for the screenshot.
Source of Dataset (in its original form): https://opendata-renewables.engie.com/
License: Open License version 2.0 published by Etalab: https://www.etalab.gouv.fr/wp-content/uploads/2018/11/open-licence.pdf